SEO
The What, Why And How The Heck?! Of robots.txt Files For SEO

It’s safe to say, with all its different elements, SEO is a multi-discipline area of digital marketing where creativity meets technical knowledge. While many SEOs love the human element, there’s no denying the technical aspects that can be the secret to significantly better results for your clients.
robots.txt files are the perfect example of technical SEO that is sometimes overlooked because it seems too complicated, but can be instrumental in boosting your search performance. But why? Here’s what we know.
Simply put, this file tells search engines what they can and can’t crawl. First introduced in 1994, it has remained relevant to search while other technologies have fallen out of favour.
Though there is no official way to enforce the rules of a robots.txt file, the concept has been widely respected and acknowledged by web pioneers since its introduction, however, the rise of AI has eroded this somewhat.
In September 2022, RFC 9309 was published as a proposed standard for the Robots Exclusion Protocol.
We could talk about the wizardry of it, but the why is much more important.
Setting a crawl delay can help manage the crawl requests to your website servers so they do not become overloaded and slow your website down.
Blocking URLs that host duplicate content (for example product list pages with filters applied) can help prevent them from being crawled and delivered in search results which helps to prioritise the pages you want to be seen.
Whether it’s test pages that aren’t ready to be seen, log-in areas or internal search result pages, you can prevent them from being crawled to ensure privacy where required. However, if there is a link to these pages elsewhere that isn’t blocked from being crawled, then the page will be crawled and delivered in results pages unless you use robots meta tags to instruct a ‘no index’.
It’s important to remember that incorrect implementation of a robots.txt file can devastate your search results. It’s also important to remember that different crawlers interpret syntax differently, so be sure you are using the correct syntax for the crawlers you are directing.
So what does it look like to implement one of these files? Let’s go through the tech spec below. Or just fire this blog in the direction of your SEO expert! (Not got one? Let's talk!)
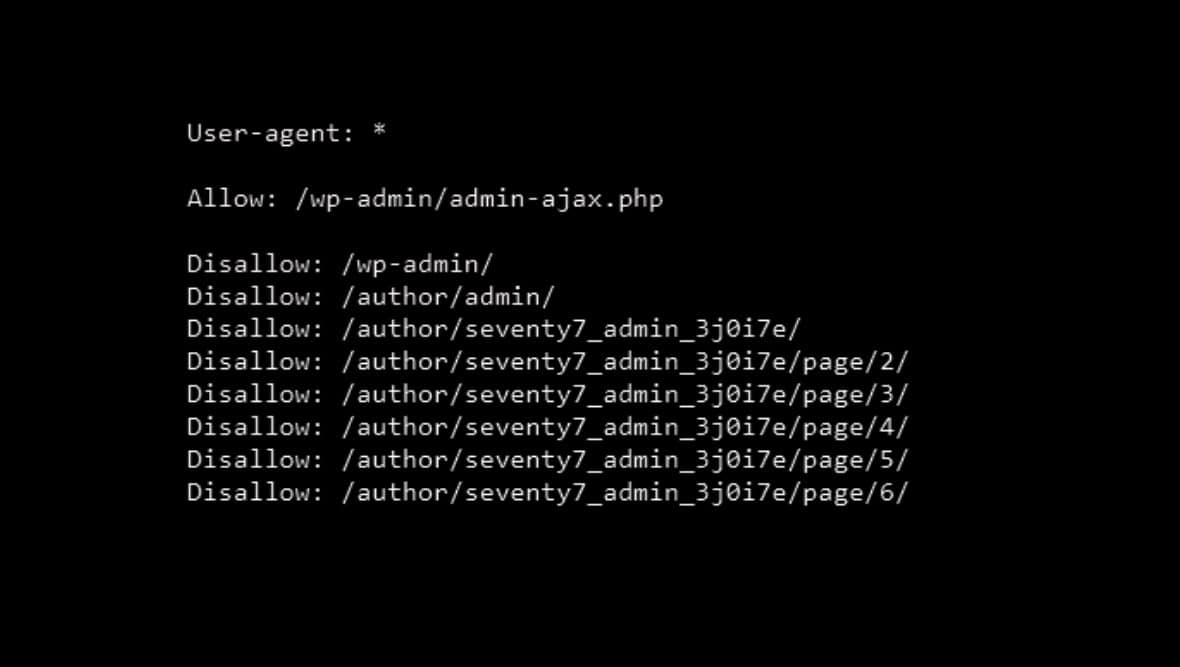
Robots.txt files should be found in the root directory of your site (www.site.com/robots.txt) and are made up of 4 elements:
Field (user-agent) : Value (*)
Directive/Rule (allow/disallow) : Path (/checkout/)
These together all make up a group. You can also group ‘user-agents’, which looks like this:
user-agent: googlebot
user-agent: bingbot
disallow: /checkout/
disallow: /*?delivery_type
This example would disallow googlebot and bingbot from crawling /checkout/ and all URLs ending with the ?delivery_type parameter.
The ‘user-agent’ specifies the specific crawler, the field is case insensitive. For those who are unfamiliar, a crawler is a software program that search engines use to scan content uploaded to the web. Googlebot is the clever little crawler bot that allows your website to appear in Google results pages (Bing, Yahoo, Baidu, DuckDuckGo etc, all have their own bots).
user-agent: googlebot
The ‘value’ (*) is a wildcard representing any characters' sequence.
user-agent: *
disallow:
This example would allow all web crawlers access to all content.
The ‘directive/rule’ instructs the crawler on what to do. For example, you can ‘disallow’ or ‘allow’ the crawler to crawl certain pages. Directives are also case insensitive but word errors aren't accepted so spelling accuracy is key.
user-agent: *
disallow: /page-to-be-blocked-from-crawling
This example would disallow all web crawlers from crawling the URL specified.
The ‘path’ allows you to specify the URL pathway. The URL is case-sensitive and should always start with '/' or * to begin the path.
user-agent: bingbot
disallow: /checkout/
This example would stop the bingbot crawler from crawling the URL path specified.
So should you or shouldn’t you? We think it’s a must for larger sites but can also be valuable for smaller sites to prioritise key pages.
Still not sure where to start? We can help. Get in touch today and find out how we can work together to maximise the impact of your digital marketing approach.



Parish Rooms,
Niven St.
Manchester,
M12 6PQ
+44 (0) 161 273 7551
The Piper Building
Peterborough Road,
London,
SW6 3EF
+44 (0) 20 7751 8600
03, Siddhi CHS Ltd,
Mhada Malad East
near Wageshwari Temple,
Khadakpada,
(W) Mumbai
400097